分库分表相关问题
实际项目中的拆分情况?
水平拆分,所有表结构都一样,一般拆分有两种,一种是按照range来分,比如时间,但是这样会导致最新的数据落在某个表,压力不均匀;另一种是hash分法,利用取模来划分数据表,这样的好处是所有表的压力会均匀分配,但是后期如果扩容需要数据迁移。
分库分表中间件
sharding-jdbc:当当网开源插件,在客户端使用,不需要单独部署,运维成本低,就是一个jar包。
mycat:属于proxy层的解决方案,需要单独部署和维护,但是代码侵入性低。
不停机的数据迁移
首先,之前所有的增删改操作,除了对于旧库的操作,都加上对于新库的操作。 再写一套导数的工具,部署后,跑起来把旧库数据写入到新库中,反复循环,直到两个库数据最终一直。 当数据最终完全一致后,把代码恢复到之前的代码,再部署一次,就都ok了。
Mysql主从复制
- 主库将变更写入到主库的二进制文件中
- 从库读取主库中的二进制文件存储到relay log(中继日志)中
- 从库读取relay log(中继日志)中的内容然后完成数据的重放
Mysql读写分离
- 实现读写分离,主库写,从库读
- 由开发人员根据业务的不同来连接不同的服务器
- 使用中间件DB Proxy来完成读写分离:mysql proxy、one proxy等
- 读服务器负载均衡
分库分表
中间件sharding-jdbc配置所有库的信息以及所有库和表的路由信息,为每个表配置库和表的路由信息。
// 配置db_0
<bean id="dbtbl_0" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://192.168.3.112:3306/dbtb"/>
<property name="username" value="ubuntu"/>
<property name="password" value="ubuntu"/>
</bean>
// 配置db_1
<bean id="dbtbl_1" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://192.168.3.113:3306/dbtb"/>
<property name="username" value="ubuntu"/>
<property name="password" value="ubuntu"/>
</bean>
// 配置db_2
<bean id="dbtbl_2" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://192.168.3.114:3306/dbtb"/>
<property name="username" value="ubuntu"/>
<property name="password" value="ubuntu"/>
</bean>
// 数据库路由规则
<rdb:strategy id="databaseStrategy" sharding-columns="user_id" algorithm-expression="dbtbl_${user_id.longValue() % 3}"/>
// 字段路由规则1
<rdb:strategy id="orderTableStrategy" sharding-columns="order_id" algorithm-expression="t_order_${order_id.longValue() % 2}"/>
// 字段路由规则2
<rdb:strategy id="orderItemTableStrategy" sharding-columns="order_id" algorithm-class="com.dangdang.ddframe.rdb.sharding.example.config.spring.algorithm.SingleKeyModuloTableShardingAlgorithm"/>
<rdb:data-source id="shardingDataSource">
<rdb:sharding-rule data-sources="dbtbl_0,dbtbl_1,dbtbl_2">
<rdb:table-rules>
// 表1配置库和表的路由规则
<rdb:table-rule logic-table="t_order" actual-tables="t_order_${0..1}" database-strategy="databaseStrategy" table-strategy="orderTableStrategy"/>
// 表2配置库和表的路由规则
<rdb:table-rule logic-table="t_order_item" actual-tables="t_order_item_0,t_order_item_1" database-strategy="databaseStrategy" table-strategy="orderItemTableStrategy"/>
</rdb:table-rules>
</rdb:sharding-rule>
</rdb:data-source>
分库分表Id主键如何生成
如果分库的每个库的每个表的id都是自增,那么id就会重复
解决办法:
-
单独一个存放id的表
单独找个表存放所有表的id,每次给业务表里插入数据前先给这个表插入一条无关痛痒的数据,然后这个表给你返回一个id,你那么这个id就是你的分表的id。操作简单但是有瓶颈,适合并发小但是数据量大的系统
-
uuid
字符串类型,本地数据库生成方便,但太长不适合作为主键。适合随机生成文件名啥的
-
获取当前系统时间
获取当前时间再结合业务来获取,比如:time + 订单号 + 用户id + 业务含义编码
-
Snowflake算法
是一个64位的long型的id
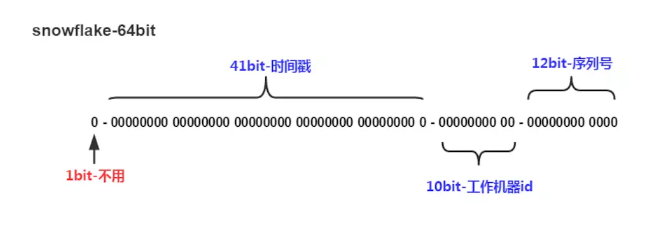
上面64个字节分为四部分
第一部分一个字节:用来标识是否可用
第二部分是41个字节:它是将当前时间的时间戳转化成2进制
第三部分是十个字节:分为两个五个字节,前五个可以代表机房id后五个代表机器id
第四部分是十二个字节:代表的是序列号,指的是某个时间点某个机房的某个机器发来的第几个请求